Introducing Marketplaces
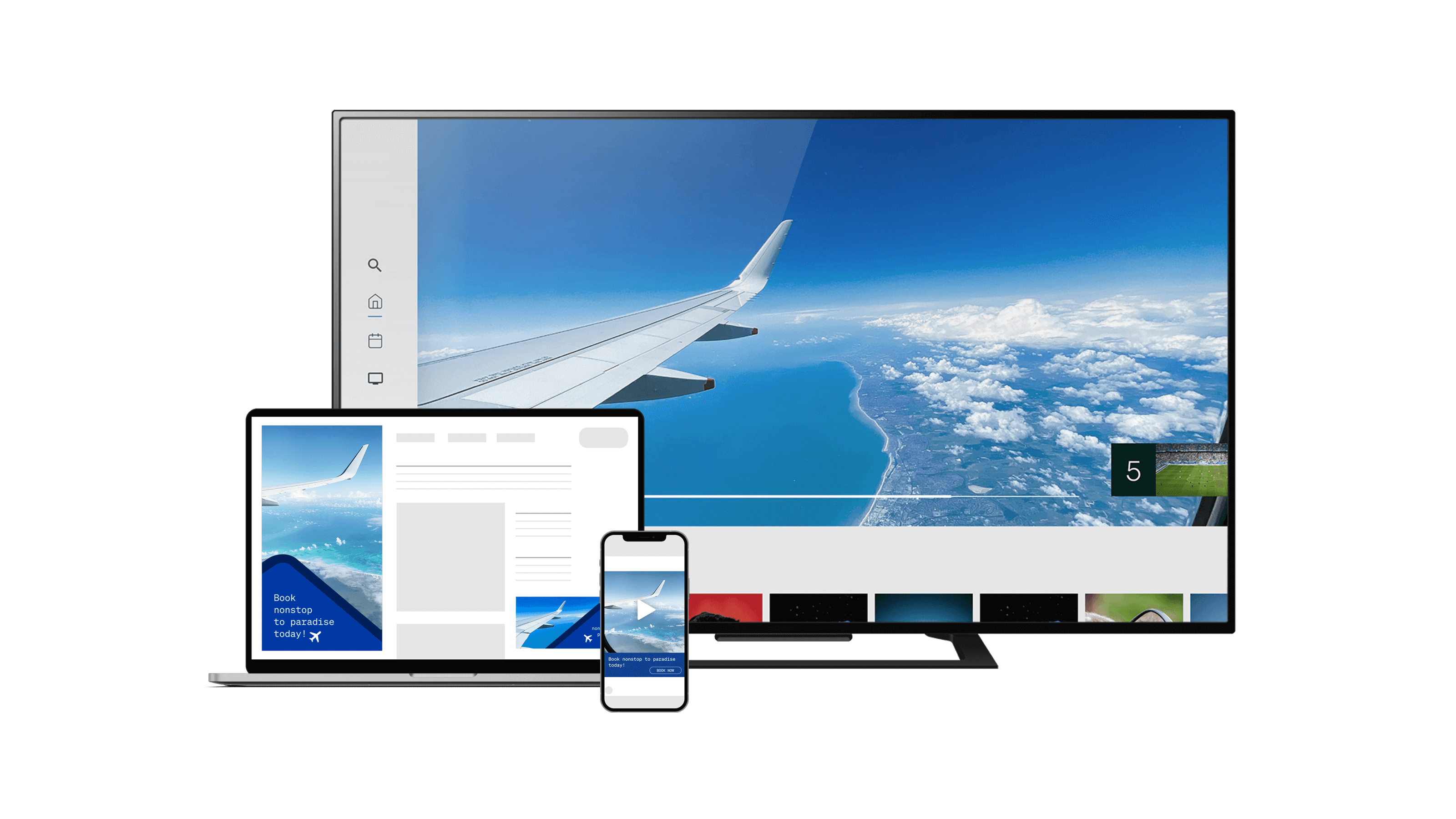
Create new media opportunities with your unique offering and premium omnichannel supply via Index, all without requiring development work.
Read nowRealise the true value of streaming TV through our dynamic marketplace, designed for precise delivery and maximised yield.



Create new media opportunities with your unique offering and premium omnichannel supply via Index, all without requiring development work.
Read nowOur ad exchange enables media owners to grow revenue and marketers to reach consumers on any screen, through any ad format.

We’re dedicated to building a safe and transparent omnichannel marketplace that provides a trusted experience for consumers.

The new PLCMT video definitions, which the IAB Tech Lab updated last year, provide a consolidated breakdown of video ad …
Read more
In our new “Behind the Tech” blog series, we’re delving into the minds of our engineering team members to get …
Read more
Can women have it all? This was the question posed to Simone Payne – Powell, director, people and global head …
Read more